Recursive vs. Iterative DFS: A Performance Surprise
Introduction
Solving LeetCode challenges has become one of my hobbies. A significant portion of these challenges requires implementing some form of Depth-First Search (DFS). DFS is an algorithm that traverses a graph or tree structure, starting at the root node and exploring as far as possible along each branch before backtracking. Generally speaking, there are two main ways to implement DFS: recursion and using a stack data structure. Common knowledge suggests that using a stack data structure is the recommended approach, as it eliminates function call overhead and mitigates the risk of stack overflow exceptions that can occur with deep recursion. However, after solving a number of challenges, I noticed an intriguing pattern: my solutions using the supposedly more optimal stack-based implementation often ran slower than simpler recursive versions submitted by other users. This observation persisted even when my approach had theoretical advantages in terms of implementation efficiency and sometimes even algorithmic complexity. Initially, I explained these unexpected results to LeetCode’s multi-tenant platform, where simultaneous users might impact individual code submission runtimes. However, as this pattern continued to emerge over time, I began to suspect that there might be more to this phenomenon than just multi-tenancy issues.
As my primary programming language is C#, I quickly prepared two versions of a complete binary tree traversal algorithm: one using recursion and another using a stack data structure. The initial results were surprising – the recursive version executed more than four times faster than its stack-based counterpart. However, I suspect this wasn’t a definitive experiment. C# stack data structures have additional features like boundary checks, which add overhead and skew the results. This realization prompted me to conduct a more sophisticated investigation using C++ and various tree configurations. So, to ensure a more controlled and insightful experiment, I decided to:
- Use C++ for its closer to hardware nature and better control over optimizations.
- Use Google Benchmark library to avoid invention the wheel.
- Implement few versions of the tree traversal algorithm, recursive implementation and couple stack-based iterative implementation.
- Measure CPU related metrics like branch prediction and cache usage, because even at this early stage, my initial hypothesis centered around these specific CPU features.
- Test with different tree configurations, maintaining a similar total node count for comparable results while varying tree height and node distribution probability. This approach creates a spectrum from dense, balanced trees to sparse, potentially imbalanced structures.
Tree Setup
I have started with implementation of binary tree generator - benchmark setup function. This generator allows for the creation of trees with various configurations, enabling a thorough investigation of how different tree structures impact the performance of recursive and iterative traversal algorithms.
Tree Node Structure
struct Node {
Node* left;
Node* right;
int val;
};
This defines a simple binary tree node structure. Each node contains a pointers to the left and to the right child nodes, plus an integer value, serving as the node’s data.
Globals
const int TREE_HEIGHT = 50;
const double FULL_PROBABILITY = 0.48;
static Node* gTreeRoot = nullptr;
static default_random_engine dre1{13};
static uniform_real_distribution<> urd1(0.0, 1.0);
static default_random_engine dre2{13};
static uniform_real_distribution<> urd2(0.0, 1.0);
static int nodes = 1;
This code sets up the parameters and variables for generating test binary tree:
TREE_HEIGHT- defines the maximum depth of the tree.FULL_PROBABILITY- determines the likelihood of a node having both left and right children.gTreeRoot= a pointer to the root node of our tree, initially set to null.- (
dre1,dre2) and (urd1,urd2) - two random number engines and uniform real distributions, both seeded with13for reproducibility. nodes- a counter to keep track of the total number of nodes.
Tree Setup Function
static void setup(Node* node, int level) {
if (level > TREE_HEIGHT)
return;
++nodes;
if (urd1(dre1) <= FULL_PROBABILITY) {
node->left = new Node {.val = level};
setup(node->left, level + 1);
node->right = new Node {.val = level};
setup(node->right, level + 1);
} else {
if (urd2(dre2) <= 0.5) {
node->left = new Node {.val = level};
setup(node->left, level + 1);
} else {
node->right = new Node {.val = level};
setup(node->right, level + 1);
}
}
}
static void setup(const benchmark::State& state) {
if (gTreeRoot)
return;
gTreeRoot = new Node {.val = 0};
setup(gTreeRoot, 1);
cout << "Tree Height: " << TREE_HEIGHT << endl;
cout << "Probability: " << FULL_PROBABILITY << endl;
cout << "Total Nodes: " << nodes << endl;
}
The first recursive function is the core of tree generation algorithm. The function takes a node pointer to current node and the current tree level as parameters. It first checks if we’ve exceeded the maximum tree height. With probability FULL_PROBABILITY, it creates both left and right children, otherwise, it randomly creates either a left or right child with equal probability. For each created child, it recursively calls itself, incrementing the level.
This approach generates a semi-random tree structure, allowing for a mix of full and partial nodes. The randomness helps simulate various scenarios while maintaining some control over the tree structure and height.
The second function is used by Benchmark library and initializes the tree if it hasn’t been created yet. It creates the root node and calls the previous recursive setup function. Finally, it outputs the tree’s characteristics for reference.
DFS Implementations
Recursion based implementation
The recursive DFS implementation consists of two key functions:
int dfs_recursion(Node* node)- do the DFS itself.void bm_dfs_recursion(benchmark::State& state)- entry function for Benchmark library.
static int dfs_recursion(Node* node) {
int c = 1;
if (node->left)
c += dfs_recursion(node->left);
if (node->right)
c += dfs_recursion(node->right);
return c;
}
This function performs a typical recursive DFS traversal of the binary tree. If left child exists, it recursively calls itself on the left subtree. It does the same for the right child if it exists. Finally, it returns the total count of nodes in the subtree rooted at the current node.
static void bm_dfs_recursion(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_recursion(gTreeRoot));
}
This function is designed to benchmark the recursive DFS implementation. It uses a benchmarking loop provided by the benchmark library. Inside the loop, it calls dfs_recursion on the global tree root (gTreeRoot). The benchmark::DoNotOptimize function is used to prevent the compiler from optimizing away the function call, ensuring accurate timing measurements.
Stack based implementation using std::vector
For iterative DFS implementation C++’s std::vector is used as a stack.
static int dfs_vector(Node* root) {
int c = 0;
Node* node;
gVector.push_back(root);
do {
node = gVector.back();
gVector.pop_back();
++c;
if (node->left)
gVector.push_back(node->left);
if (node->right)
gVector.push_back(node->right);
} while (gVector.size());
return c;
}
static void bm_dfs_vector(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_vector(gTreeRoot));
}
Key points of this implementation:
- It uses a global vector
gVectoras stack (global static for simplicity, there is no race-condition here). It’s worth noting that this vector was pre-allocated with sufficient capacity to prevent unnecessary memory re-allocations during the tests, which could skew performance measurements. - The
dfs_vectorfunction provides a typical DFS implementation via stack data structure. Starts by pushing the root node onto the stack. Enters a do-while loop that continues until the stack is empty. In each iteration pops the last node from the stack, increments the counter, pushes the left and right children (if they exist) onto the stack. Finally it returns the total count of nodes traversed. - The benchmark function
bm_dfs_vectoris similar to the recursive version, using the Benchmark library to measure the performance of stack-based DFS implementation.
Stack-based implementation using self-made stack on array
To further optimize iterative DFS approach and minimize potential overhead from std::vector, I implemented a custom stack using a pre-allocated array. This method gives me more control over memory usage.
static int dfs_my_stack(Node* root) {
int c = 0;
Node **top = myStack;
Node node;
*top = root;
do {
node = **top--;
++c;
if (node.left)
*++top = node.left;
if (node.right)
*++top = node.right;
} while (top >= myStack);
return c;
}
static void bm_dfs_my_stack(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_my_stack(gTreeRoot));
}
The implementation is one-to-one to previous one except the stack is implemented using array and top pointer to track the first element of the stack.
Compilation & Run
g++ with additional flags is used to compile the program:
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
-std=c++11- this flag sets the C++ standard to C++11, it ensures that C++11 features are available and that the code is compiled according to the C++11 standard.-O3- this enables level 3 optimizations, it’s one of the highest general optimization levels, which aggressively optimizes for both speed and size. It includes all optimizations from lower levels (-O1 and -O2) and adds more aggressive optimizations such as function inlining, constant propagation, and loop unrolling.-fno-optimize-sibling-calls- this flag disables the optimization of sibling and tail recursive calls, this is crucial for our experiment as it prevents the compiler from automatically transforming our recursive function into an iterative one, which would defeat the purpose of comparing recursive and iterative implementations.-lbenchmark- this links against the Google Benchmark library, which we’re using for performance measurements.-lpthread- this links against the POSIX threads library, it’s required by the benchmark library for multi-threaded benchmarking capabilities however they are not used.-lpfm- this links against the Performance Application Programming Interface (PAPI) library. PAPI provides tools for measuring hardware performance counters, which can give detailed insights into how our code is executing at the CPU level.
To run the program the following command has been used:
sudo benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
benchmark_perf_counters flag set to show CPU counters for cycles, instructions, branches information and page-faults.
Results
The benchmark tests have been run 7 times with for different tree height and tree completeness probabilities:
Height: 27, Probability: 1.0000, Nodes: 134217728Height: 50, Probability: 0.4800, Nodes: 277042369Height: 100, Probability: 0.1900, Nodes: 212716301Height: 500, Probability: 0.0360, Nodes: 235645027Height: 1000, Probability: 0.0155, Nodes: 246802640Height: 2000, Probability: 0.0080, Nodes: 285218489Height: 4000, Probability: 0.0036, Nodes: 338867727
Here are the raw results from tests:
# 27 1.0
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:09:21+02:00
Running ./benchmark
Run on (8 X 4494.17 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 0.90, 0.89, 0.94
Tree Height: 27
Probability: 1
Total Nodes: 134217728
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 527086383 ns 527055819 ns 2 BRANCH-MISSES=36.553k BRANCHES=608.454M CYCLES=2.07423G INSTRUCTIONS=2.53224G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 1735172091 ns 1735102972 ns 2 BRANCH-MISSES=15.2496M BRANCHES=1.07374G CYCLES=7.33513G INSTRUCTIONS=4.83184G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 1693223170 ns 1693163154 ns 2 BRANCH-MISSES=22.434M BRANCHES=939.525M CYCLES=7.10886G INSTRUCTIONS=3.7581G PAGE-FAULTS=0
# 50 0.48
```bash
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:07:43+02:00
Running ./benchmark
Run on (8 X 4529.77 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 0.81, 0.87, 0.94
Tree Height: 50
Probability: 0.48
Total Nodes: 277042369
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 2221031443 ns 2220955364 ns 2 BRANCH-MISSES=197.951M BRANCHES=1.04709G CYCLES=8.77535G INSTRUCTIONS=4.72115G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 4317284431 ns 4317150975 ns 2 BRANCH-MISSES=273.825M BRANCHES=1.64012G CYCLES=17.8608G INSTRUCTIONS=7.38053G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 4780048835 ns 4779896050 ns 2 BRANCH-MISSES=277.2M BRANCHES=1.43512G CYCLES=20.1796G INSTRUCTIONS=5.74044G PAGE-FAULTS=0
# 100 0.19
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:10:51+02:00
Running ./benchmark
Run on (8 X 4610.07 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 1.09, 0.94, 0.95
Tree Height: 100
Probability: 0.19
Total Nodes: 212716301
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 1861686070 ns 1861580568 ns 2 BRANCH-MISSES=205.224M BRANCHES=601.965M CYCLES=7.55931G INSTRUCTIONS=2.59222G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 3014304973 ns 3014008552 ns 2 BRANCH-MISSES=197.542M BRANCHES=1.01258G CYCLES=12.4533G INSTRUCTIONS=4.5566G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 3083081877 ns 3082991216 ns 2 BRANCH-MISSES=205.326M BRANCHES=886.017M CYCLES=13.1098G INSTRUCTIONS=3.54404G PAGE-FAULTS=0
# 500 0.036
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:15:27+02:00
Running ./benchmark
Run on (8 X 4100.53 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 1.02, 1.04, 1.00
Tree Height: 500
Probability: 0.036
Total Nodes: 235645027
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 1968057844 ns 1967889400 ns 2 BRANCH-MISSES=204.206M BRANCHES=603.93M CYCLES=7.6194G INSTRUCTIONS=2.66957G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 2055138503 ns 2054940644 ns 2 BRANCH-MISSES=140.266M BRANCHES=976.527M CYCLES=8.33899G INSTRUCTIONS=4.39437G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 2039090559 ns 2038915606 ns 2 BRANCH-MISSES=140.1M BRANCHES=854.469M CYCLES=8.36145G INSTRUCTIONS=3.41786G PAGE-FAULTS=0
# 1000 0.0155
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:17:55+02:00
Running ./benchmark
Run on (8 X 4392.57 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 1.12, 1.04, 1.01
Tree Height: 1000
Probability: 0.0155
Total Nodes: 246802640
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 1862077412 ns 1862055577 ns 2 BRANCH-MISSES=212.036M BRANCHES=623.695M CYCLES=7.63219G INSTRUCTIONS=2.76738G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 1739592824 ns 1739557192 ns 2 BRANCH-MISSES=134.632M BRANCHES=1.00252G CYCLES=6.9701G INSTRUCTIONS=4.51132G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 1735287324 ns 1735271336 ns 2 BRANCH-MISSES=133.538M BRANCHES=877.212M CYCLES=7.05787G INSTRUCTIONS=3.50883G PAGE-FAULTS=0
# 2000 0.008
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:20:46+02:00
Running ./benchmark
Run on (8 X 4101.2 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 0.83, 0.94, 0.97
Tree Height: 2000
Probability: 0.008
Total Nodes: 285218489
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 2255479284 ns 2255415499 ns 2 BRANCH-MISSES=246.379M BRANCHES=717.041M CYCLES=8.69695G INSTRUCTIONS=3.18602G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 1863869539 ns 1863822470 ns 2 BRANCH-MISSES=150.065M BRANCHES=1.15001G CYCLES=7.43685G INSTRUCTIONS=5.17503G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 1858872832 ns 1858840804 ns 2 BRANCH-MISSES=148.696M BRANCHES=1.00627G CYCLES=7.54222G INSTRUCTIONS=4.02504G PAGE-FAULTS=0
# 4000 0.0036
g++ benchmark.cpp -std=c++11 -O3 -fno-optimize-sibling-calls -lbenchmark -lpthread -lpfm -o benchmark
sudo ./benchmark --benchmark_perf_counters=CYCLES,INSTRUCTIONS,BRANCHES,BRANCH-MISSES,PAGE-FAULTS
2024-07-23T23:30:55+02:00
Running ./benchmark
Run on (8 X 3700.07 MHz CPU s)
CPU Caches:
L1 Data 32 KiB (x4)
L1 Instruction 32 KiB (x4)
L2 Unified 256 KiB (x4)
L3 Unified 8192 KiB (x1)
Load Average: 1.28, 1.17, 1.06
Tree Height: 4000
Probability: 0.0036
Total Nodes: 338867727
-------------------------------------------------------------------------------------------
Benchmark Time CPU Iterations UserCounters...
-------------------------------------------------------------------------------------------
bm_dfs_recursion/iterations:2 2458095607 ns 2457901073 ns 2 BRANCH-MISSES=287.38M BRANCHES=849.303M CYCLES=10.0689G INSTRUCTIONS=3.77683G PAGE-FAULTS=0
bm_dfs_vector/iterations:2 2104637432 ns 2104433798 ns 2 BRANCH-MISSES=174.026M BRANCHES=1.36035G CYCLES=8.3376G INSTRUCTIONS=6.12156G PAGE-FAULTS=0
bm_dfs_my_stack/iterations:2 2095098177 ns 2094852956 ns 2 BRANCH-MISSES=172.723M BRANCHES=1.19031G CYCLES=8.43727G INSTRUCTIONS=4.76123G PAGE-FAULTS=0
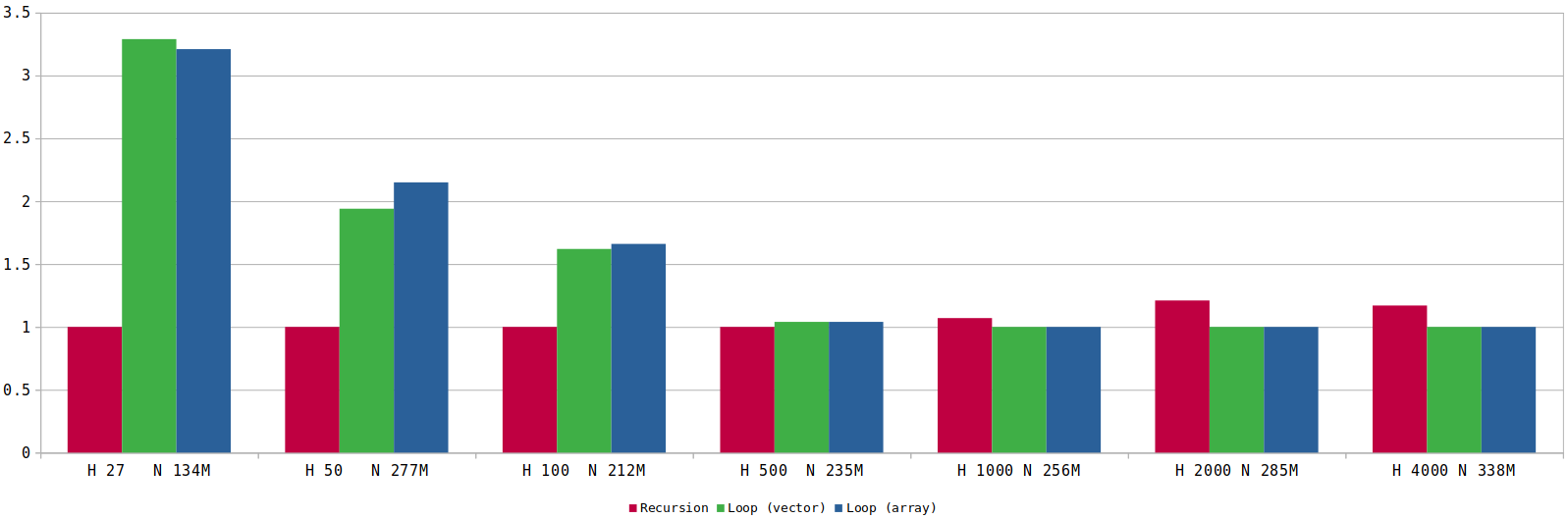
For better comparison, I compiled the results into a graph. This visualization encapsulates the performance characteristics of each method relative to one another, showing a clear picture of how tree size and structure influence implementation speed. In the graph below, each group of bars represents a distinct experiment, with the height (H) and total number of nodes (N) of the tree indicated. The fastest algorithm for each configuration serves as the baseline (1.0), allowing to easily compare relative performance.
Key Takeaways
In dense trees (like the first test with 27 height and 1.0 probability), the recursive approach significantly outperforms the stack-based methods. As the trees become sparser (lower probability values in subsequent tests), the performance gap between recursive and iterative approaches narrows considerably. In the sparsest cases (like height 4000 with 0.0036 probability), the stack-based methods actually outperform the recursive approach.
Analysis of CPU metrics suggests that the primary factor in this performance difference is CPU branch prediction. Dense trees likely allow for more efficient use of CPU branch prediction in the recursive version. The recursive approach generally has fewer branches and instructions, which explains its efficiency on denser trees. However, as trees become more sparse, more branch mispredictions occur, and the overhead of function calls becomes increasingly significant. In contrast, the stack-based approaches demonstrate more consistent branch prediction performance across different tree densities.
As a Final Note
The goal of sharing these results is not to make sweeping generalizations or universal recommendations, but rather to provide insights into the performance trade-offs that can occur in different scenarios. A specially provide insights on how internal CPU “magic” could impact the performance and why it is matter.
As with any optimization effort, it’s crucial to profile and benchmark within the context of your specific use case. These results serve as a starting point for understanding potential performance implications, but they should not be taken as definitive for all situations. The best approach for your particular needs may depend on a variety of factors beyond raw performance, including code maintainability and the specific requirements of your application.
I would be glad to hear your observations in this area and would appreciate it if you could point out any benchmarking issues you have noticed in this article.
Full code with additional methods used during the tests (benchmark.cpp)
#include <benchmark/benchmark.h>
#include <iostream>
#include <queue>
#include <stack>
#include <cstdlib>
#include <random>
#include <vector>
using namespace std;
struct Node
{
Node* left;
Node* right;
int val;
};
/*
27 1.0
50 0.48
100 0.19
500 0.036
1000 0.0155
2000 0.008
4000 0.0036
*/
const int TREE_HEIGHT = 4000;
const double FULL_PROBABILITY = 0.0036;
const int STACK_CAPACITY = TREE_HEIGHT * 10;
static Node* gTreeRoot = nullptr;
static Node** myStack = new Node*[STACK_CAPACITY];
static stack<Node*> gStack;
static queue<Node*> gQueue;
static vector<Node*> gVector;
static default_random_engine dre1{13};
static uniform_real_distribution<> urd1(0.0, 1.0);
static default_random_engine dre2{13};
static uniform_real_distribution<> urd2(0.0, 1.0);
static int nodes = 1;
static void setup(Node* node, int level) {
if (level > TREE_HEIGHT)
return;
++nodes;
if (urd1(dre1) <= FULL_PROBABILITY) {
node->left = new Node {.val = level};
setup(node->left, level + 1);
node->right = new Node {.val = level};
setup(node->right, level + 1);
} else {
if (urd2(dre2) <= 0.5) {
node->left = new Node {.val = level};
setup(node->left, level + 1);
} else {
node->right = new Node {.val = level};
setup(node->right, level + 1);
}
}
}
static void setup(const benchmark::State& state) {
if (gTreeRoot)
return;
gTreeRoot = new Node {.val = 0};
setup(gTreeRoot, 1);
cout<<"Tree Height: "<<TREE_HEIGHT<<endl;
cout<<"Probability: "<<FULL_PROBABILITY<<endl;
cout<<"Total Nodes: "<<nodes<<endl;
for (int i = 1; i <= STACK_CAPACITY; ++i) {
gStack.push(nullptr);
gQueue.push(nullptr);
}
for (int i = 1; i <= STACK_CAPACITY; ++i) {
gStack.pop();
gQueue.pop();
}
gVector.reserve(STACK_CAPACITY);
}
static int dfs_recursion_v1(Node* node) {
if (!node)
return 0;
int c = 1;
c += dfs_recursion_v1(node->left);
c += dfs_recursion_v1(node->right);
return c;
}
static void bm_dfs_recursion_v1(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_recursion_v1(gTreeRoot));
}
static int dfs_recursion_v2(Node* node) {
int c = 1;
if (node->left)
c += dfs_recursion_v2(node->left);
if (node->right)
c += dfs_recursion_v2(node->right);
return c;
}
static void bm_dfs_recursion_v2(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_recursion_v2(gTreeRoot));
}
static int dfs_stack(Node* root) {
int c = 0;
Node* node;
gStack.push(root);
do {
node = gStack.top();
gStack.pop();
++c;
if (node->left)
gStack.push(node->left);
if (node->right)
gStack.push(node->right);
} while (gStack.size());
return c;
}
static void bm_dfs_stack(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_stack(gTreeRoot));
}
static int bfs_queue(Node* root) {
int c = 0;
Node* node;
gQueue.push(root);
do {
node = gQueue.front();
gQueue.pop();
++c;
if (node->left)
gQueue.push(node->left);
if (node->right)
gQueue.push(node->right);
} while (!gQueue.empty());
return c;
}
static void bm_bfs_queue(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(bfs_queue(gTreeRoot));
}
static int dfs_vector(Node* root) {
int c = 0;
Node* node;
gVector.push_back(root);
do {
node = gVector.back();
gVector.pop_back();
++c;
if (node->left)
gVector.push_back(node->left);
if (node->right)
gVector.push_back(node->right);
} while (gVector.size());
return c;
}
static void bm_dfs_vector(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_vector(gTreeRoot));
}
static int dfs_my_stack(Node* root) {
int c = 0;
Node **top = myStack;
Node node;
*top = root;
do {
node = **top--;
++c;
if (node.left)
*++top = node.left;
if (node.right)
*++top = node.right;
} while (top >= myStack);
return c;
}
static void bm_dfs_my_stack(benchmark::State& state) {
for (auto _ : state)
benchmark::DoNotOptimize(dfs_my_stack(gTreeRoot));
}
BENCHMARK(bm_dfs_recursion_v1)->Iterations(2)->Setup(setup);
BENCHMARK(bm_dfs_recursion_v2)->Iterations(2)->Setup(setup);
BENCHMARK(bm_dfs_stack)->Iterations(2)->Setup(setup);
BENCHMARK(bm_bfs_queue)->Iterations(2)->Setup(setup);
BENCHMARK(bm_dfs_vector)->Iterations(2)->Setup(setup);
BENCHMARK(bm_dfs_my_stack)->Iterations(2)->Setup(setup);
BENCHMARK_MAIN();
Leave a comment